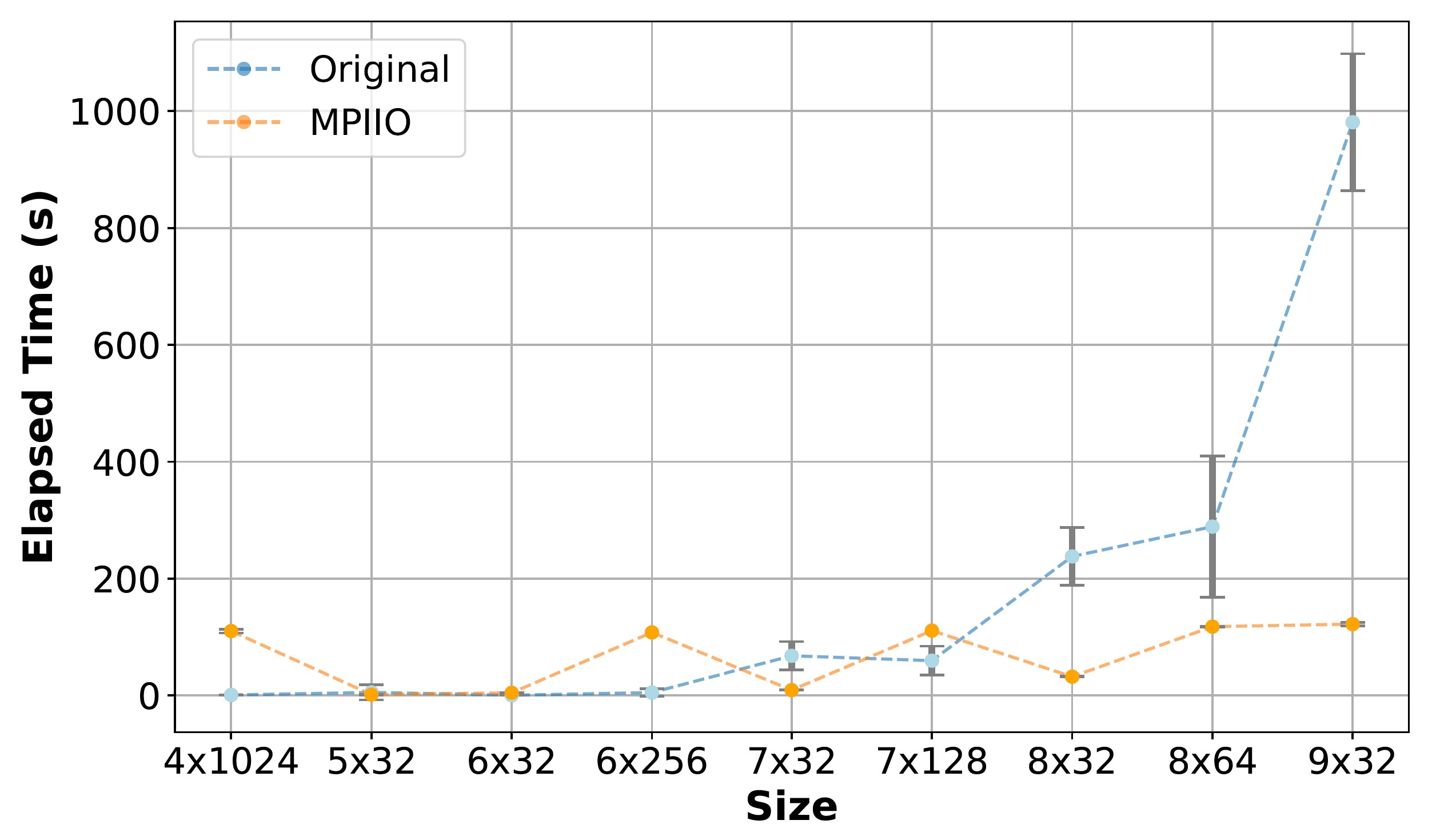
Highlights
We developed a kernel code to mimic the I/O behavior of multiscale simulations.
Such an I/O kernel is useful for HPC research, as it can be executed more easily
and more efficiently than the full simulations when researchers are interested
in the I/O load only. We validate the kernel code by comparing it to the I/O performance
of an actual simulation, and we then use it to test some possible improvements to the
output routine of the MHM (Multiscale Hybrid Mixed) library, such as the use of the MPI/IO library.
The HPCProSol - Next-generation HPC PROblems and SOLutions - is an Associate Team
coordinated by Carla Osthoff from LNCC and Francieli Zanon-Boito from
Inria TADAAM team. In the context of the convergence of HPC and big data, the
notion of scientific application is evolving into a scientific workflow,
composed of cpu-intensive and data-intensive tasks. In this new scenario,
the already challenging problems of efficiently managing resources are expected
to become worse and should be tackled by better scheduling at application and
system levels, and consider applications’ characteristics to avoid issues such
as interference. HPCProSol is a collaboration between the TADaaM Inria team and
the LNCC to study and characterize the new HPC workload, represented by a set of
scientific applications that are important to the LNCC. This includes the MHM
method. This study will guide the proposal of monitoring and profiling techniques
for applications, and the design of new coordination mechanisms to
arbitrate resources in HPC environments.
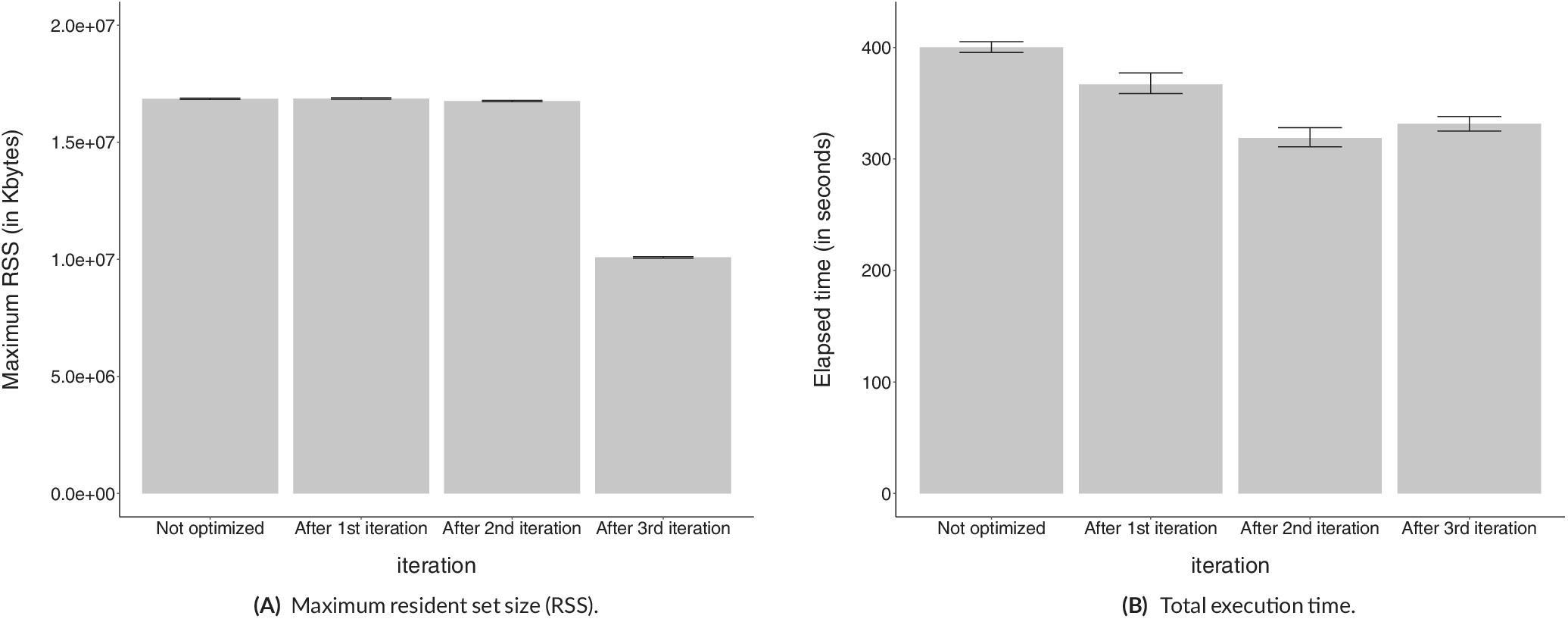
We proposed and analyzed computationally a new method for identifying, locating, characterizing and correcting memory allocation anomalies, and a tool that HPC application developers can use to apply the method. The method is iterative, in the sense that at each iteration a specific allocation size and code region are chosen for the employement of the method. The set of MHM libraries (MSL) was the main target of the method: we showed (see figures below) that its employment reduced the memory footprint of MSL-based simulators by 37.27% and its execution time by 16.52%. This work received an award for being among the best 4 papers in the IX Brazilian Symposium on High-Performance Computing Systems (WSCAD 2019). More information.